The C4.5 uses "Gain Ratio" measure which is Information Gain divided by SplitInfo. The Information Gain divided by SplitInfo is call GainRaTIO.
Step 1: Calculate entropy of the target.
Step 2: Split the dataset on the different attribute, and calculate GainRATIO of each attribute.
Step 3: Choose attribute that have largest GainRATIO as the decision node.
Step 4: The C4.5 algorithm is run recursively one the non-leaf branch, until all data is classified.
Step 1:
E(travel promotion) = E(4/10, 6/10) = - (0.4log20.4) - (0.6log20.6) = 0.971
Step 2:
| Gender | Yes | No |
| Male | 3 | 2 |
| Female | 3 | 2 |
E(Interest, Gender) = P(Male)*E(3/5, 2/5) + P(Female)*E(3/5, 2/5)
= 5/10*(- 0.6log20.6 - 0.4log20.4) + 5/10*(- 0.6log20.6 - 0.4log20.4) = 0.971
Gain(Original, Gender) = 0.971 - 0.971 = 0
SplitINFO(Interest, Gender) = - (5/10log25/10) - (5/10log25/10) = 1
GainRATIO(Interest, Gender) = 0/1 = 0
| Age | Yes | No |
| 21-40 | 2 | 1 |
| 41-60 | 3 | 1 |
| > 60 | 2 | 1 |
E(Interest, Age) = P(21-40)*E(2/3, 1/3) + P(41-60)*E(3/4, 1/4) + P(> 60)*E(2/3, 1/3)
= 3/10*0.9183 + 4/10*0.8113 + 3/10*0.9183 = 0.876
Gain(Original, Age) = 0.971 - 0.876 = 0.095
SplitINFO(Interest, Age) =- (3/10log23/10) - (4/10log24/10) - (3/10log23/10) = 1.571
GainRATIO(Interest, Age) = 0.095/1.571 = 0.06
| Salary | Yes | No |
| 10001-30000 | 1 | 3 |
| 30001-50000 | 3 | 1 |
| > 50001 | 2 | 0 |
E(Interest, Age) = P(10001-30000)*E(1/4, 3/4) + P(30001-50000)*E(3/4, 1/4) + P(> 50001)*E(2/2, 0/2)
= 4/10*0.811 + 4/10*0.811 + 2/10*0 = 0.649
Gain(Original, Age) = 0.971 - 0.649 = 0.322
SplitINFO(Interest, Age) =- (4/10log24/10) - (4/10log24/10) - (2/10log22/10) = 2.376
GainRATIO(Interest, Age) = 0.322/2.376 = 0.136
| Status | Yes | No |
| Married | 4 | 1 |
| Single | 2 | 3 |
E(Interest,Status) = P(Married)*E(4/5, 1/5) + P(Single)*E(2/5, 3/5)
= 5/10*0.722 + 5/10*0.971 = 0.847
Gain(Original,Status) = 0.971 - 0.847 = 0.124
SplitINFO(Interest,Status) =- (5/10log25/10) - (5/10log25/10) = 1
GainRATIO(Interest,Status) = 0.124/1 = 0.124
| Number of times travel per year | Yes | No |
| 1-3 | 3 | 4 |
| 4-5 | 3 | 0 |
E(Interest, travel per year) = P(1-3)*E(3/7, 4/7) + P(4-5)*E(3/3, 0/3)
= 7/10*0.985 + 3/10*0 = 0.69
Gain(Original, travel per year) = 0.971 - 0.69 = 0.281
SplitINFO(Interest, travel per year) =- (7/10log27/10) - (3/10log23/10) = 0.881
GainRATIO(Interest, travel per year) = 0.281/0.881 = 0.319
Step 3: GainRATIO of Number of times travel per year is come to top, so number of times travel per year is the root node.
Step 4: Next we will interest only number of times travel per year that have 1-3 value.
| Gender | Age | Salary | Status | interest travel promotion
or not |
| Male | 21-40 | 30001-50000 | Single | No |
| Female | > 60 | 10001-30000 | Single | No |
| Male | 41-60 | > 50001 | Single | Yes |
| Female | 21-40 | > 50001 | Single | Yes |
| Male | > 60 | 10001-30000 | Single | No |
| Female | 41-60 | 10001-30000 | Married | No |
| Male | > 60 | 30001-50000 | Married | Yes |
Step 5: Calculate GainRATIO that have travel per year = 1-3
E(Interest[1-3]) = E(3/7, 4/7) = - (3/7log23/7) - (4/7log24/7) = 0.985
| Gender | Yes | No |
| Male | 2 | 2 |
| Female | 2 | 1 |
E(Interest[1-3], Gender) = P(Male)*E(2/4, 2/4) + P(Female)*E(2/3, 1/3)
= 4/7*1 + 3/7*0.918 = 0.965
Gain(Original[1-3], Gender) = 0.985 - 0.965 = 0.02
SplitINFO(Interest[1-3], Gender) =- (4/7log24/7) - (3/7log23/7) = 0.985
GainRATIO(Interest[1-3], Gender) = 0.02/0.985 = 0.02
| Age | Yes | No |
| 21-40 | 1 | 1 |
| 41-60 | 1 | 1 |
| > 60 | 1 | 2 |
E(Interest[1-3], Age) = P(21-40)*E(1/2, 1/2) + P(41-60)*E(1/2, 1/2) + P(> 60)*E(1/3, 2/3)
= 2/7*1 + 2/7*1 + 3/7*0.918 = 0.965
Gain(Original[1-3], Age) = 0.985 - 0.965 = 0.02
SplitINFO(Interest[1-3], Age) =- (2/7log22/7) - (2/7log22/7) - (3/7log23/7) = 1.556
GainRATIO(Interest[1-3], Age) = 0.02/1.556 = 0.013
| Salary | Yes | No |
| 10001-30000 | 0 | 3 |
| 30001-50000 | 1 | 1 |
| > 50001 | 2 | 0 |
E(Interest[1-3], Salary) = P(10001-30000)*E(3/3, 0/3) + P(30001-50000)*E(1/2, 1/2) + P(> 50001)*E(2/2, 0/2)
= 3/7*0 + 2/7*1 + 2/7*0 = 0.286
Gain(Original[1-3],Salary) = 0.985 - 0.286 = 0.699
SplitINFO(Interest[1-3],Salary) =- (3/7log23/7) - (2/7log22/7) - (2/7log22/7) = 1.556
GainRATIO(Interest[1-3],Salary) = 0.699/1.556 = 0.449
| Status | Yes | No |
| Married | 1 | 1 |
| Single | 2 | 3 |
E(Interest[1-3], Status) = P(Married)*E(1/2, 1/2) + P(Single)*E(2/5, 3/5)
= 2/7*1 + 5/7*0.971 = 0.979
Gain(Original[1-3], Status) = 0.985 - 0.979 = 0.006
SplitINFO(Interest[1-3], Status) =- (2/7log22/7) - (5/7log25/7) = 0.863
GainRATIO(Interest[1-3], Status) = 0.006/0.863 = 0.007
Step 6: GainRATIO of salary is come to top, so salary is the child node of travel per year.
Step 7: we will interest only number of times travel per year that have 1-3 value and salary = 30001-50000.
| Gender | Age | Status | interest travel promotion
or not |
| Male | 21-40 | Single | No |
| Male | > 60 | Married | Yes |
Step 8: Calculate GainRATIO that have travel per year = 1-3 and salary = 30001-50000.
E(Interest[1-3][30001-50000]) = E(1/2, 1/2) = - (1/2log21/2) - (1/2log21/2) = 1
| Gender | Yes | No |
| Male | 1 | 1 |
| Female | 0 | 0 |
E(Interest[1-3][30001-50000], Gender) = P(Male)*E(1/2, 1/2) + P(Female)*E(0, 0) = 2/2*1 + 0 = 1
Gain(Original[1-3][30001-50000], Gender) = 1 - 1 = 0
SplitINFO(Interest[1-3][30001-50000], Gender) =- (2/2log22/2) = 0
GainRATIO(Interest[1-3][30001-50000], Gender) = 0
| Age | Yes | No |
| 21-40 | 0 | 1 |
| 41-60 | 0 | 0 |
| > 60 | 1 | 0 |
E(Interest[1-3][30001-50000], Age) = P(21-40)*E(0, 1) + P(41-60)*E(0, 0) + P(> 60)*E(1, 0) = 0
Gain(Original[1-3][30001-50000], Age) = 1 - 0 = 1
SplitINFO(Interest[1-3][30001-50000], Age) = - (1/2log22/7) - (1/2log21/2) = 1
GainRATIO(Interest[1-3][30001-50000], Age) = 1/1 = 1
| Status | Yes | No |
| Married | 1 | 0 |
| Single | 0 | 1 |
E(Interest[1-3][30001-50000], Status) = P(Married)*E(0, 1) + P(Single)*E(1, 0) = 0
Gain(Original[1-3][30001-50000], Status) = 1 - 0 = 1
SplitINFO(Interest[1-3][30001-50000], Status) =- (1/2log21/2) - (1/2log21/2) = 1
GainRATIO(Interest[1-3][30001-50000], Status) = 1
GainRATIO both age and status is equal, so we can use either age or status to child node of salary, but we should select a node that have least number of type of attribute. Therefore we got a decision tree like this.
After We constructed a decision tree completely, we can use post pruning in order to discard unreliable parts.
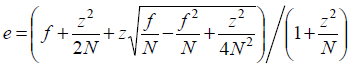
f is the error on the training data.
N is the number of instances covered by the left.
z from normal distribution.
e is error estimate for a node.
If the error estimate at children node greater than parent node, we do not want to keep the children.
The advantages of the C4.5 are:
- Builds models that can be easily interpreted and explained to executives.
- Easy to implement because construct a decision tree only once that can handle test sets.
- Can use both categorical and continuous values.
- Deals with noise.
The disadvantages are:
- Small variation in data can lead to different decision trees (especially when the variables are close to each other in value).
- Does not work very well on a small training set.
- If in the first time we use small training set to construct a tree, It can't handle a test set accurately.
Solution 1:
When test data has been predicted by decision tree, and get Yes in class interest travel promotion that means customer should have interest in a new promotion. We'll send e-mail to him/her. Since he/she rejected, the training set can't handle correctly. If number of rejection greater than threshold(incorrect predictions/correct prediction), we'll use test sets to become training sets combination with old training sets to construct a decision tree again for preparing to predict new test set.
Example
Since we define threshold=0.3, (incorrect predictions)/(correct prediction) is greater than 0.3, we'll construct decision tree immediately.
Solution 2:
Use C5.0 instead of C4.5. The advantages of C5.0
- Multi-threaded: can take advantage of multiple CPUs or cores that can improve speed to construct a decision tree.
- Boosting: that is a technique for generating and combining multiple classifiers to improve predictive accuracy.
- Decision trees generally smaller.











{kind=link}
{kind=link}